Early stages
In the early stages of development products tend to be full of bugs, not implemented functions, inconsistent design and so on. What you need the most here is good feedback: do workflows make sense? Is the UI nice? Is the program stable? But not every feedback must be implemented, not every bug will be reproduced, since it will get obsolete through other changes.
Late development stages
When your product or a new feature gets mature, less feedback is needed. It's time for hardening all bugs out of the program.
Maintainance
When the product is released and bugs occur, you spend much more time on reproducing and fixing per issue then in earlier stages. Makes sense, because such bugs are probably more complex and fixes could impact program parts severily.
How traditional bugtracking works
Most bugtrackers are web based and see every bug as a solitaire entity. You have an enormous amount of fields for categorizing bugs, for example the OS in which it occured. This is important since you may pile up hundreds of bugs if not more and you need to manage that masses. You may even have workflows for accepting and assigning bugs.
Traditional bugtracking doesn't think about how bugs are actually discovered. It doesn't separate the bugs found in a test session by a tester and a single entry bug discovered in production.
How lightweight bugtracking works
Lightweight bugtracking works at a test session level. A test run must be conducted at a work item such as a user story. That is since the test should focus on a local area. The test sessions will produce a test protocol with entries similiar to issues in a bugtracking system. The difference here is that you don't need to enter so much details, just enter the issue text, some screenshots and the severity. That is much faster. Well this alone doesn't make any sense. It does make sense when the developer fixes that bugs. It should be preferrably exactly one developer. The bugs get fixed in one batch. All bugs get fixed at once. And only the bugs that cannot be fixed in one fixing session may get piled in up the traditional bugtracker.
Quality Spy's test protocols:
When conducting a test session - either based on a test plan or exploratory - you note everything you find worth noting. This includes errors, crashes, bad UI layout, but also things you like and find positive. All this is added to the protocol:
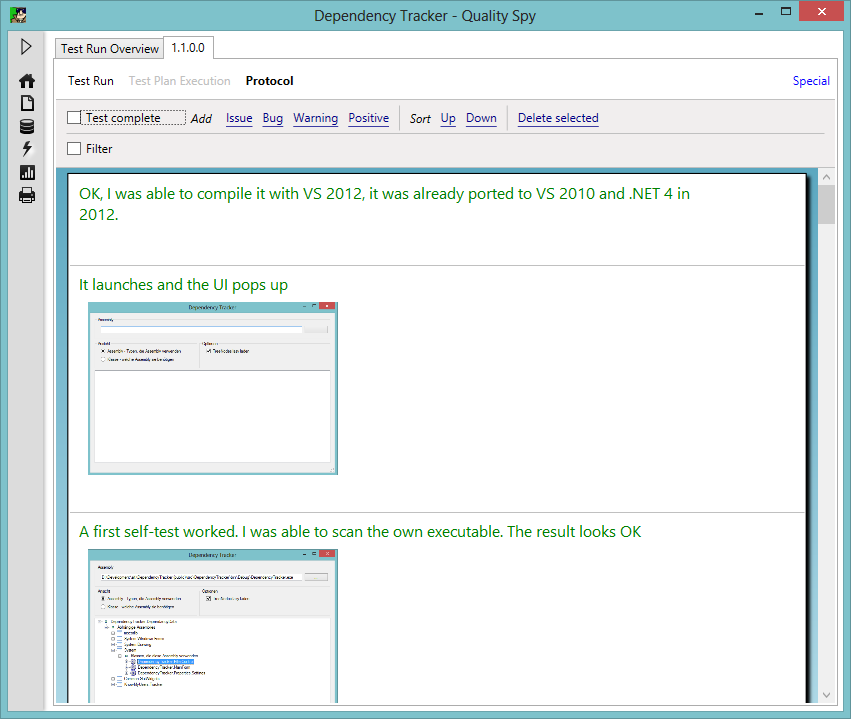

The color coding represents the severity of the issue. Red represents an error that should be fixed, orange means it is a weak point that should/could be improved, if time or budget allows.
Images play an important role, since most bugs are visible through the screen. They can be added directly from the clipboard. (compare that with the capture, save to file, upload procedure in a bugtracker...)
When the test session is complete the protocol can be handed over to the developer responsible of the feature and he can investigate issues, fix them and mark progress in the document. For that purpose the protocol can be filtered just like the lists in a bugtracker:

So the biggest difference is that not single bugs get fixed, but a series of bugs get fixed together.
Why should that be better than bugtrackers? I don't even have a bug count and what about an archive? I would argue that bugs that occured early in some development stage aren't very usefull for long term archiving. Bugs should be detected early and fixed early, that's it.
When to use it and when not
So light weight bugtracking is perfect for testing early and fixing early. Later in the game the traditional bugtracking process as described by Spolsky is perfect and desirable.
Of cause, it will only work, when the new feature was developed by exactly one developer, but this should be the case, else there is something broken in the development process. When the thing is too big, it should be broken down into valuable chunks that can be again seen as features, not just technical parts.
When used correctly lighweight bugtracking will save time and money, but more important tester and developer will feel more productive, do less tedious work and are allowed to concentrate on the important stuff - their project - not managing issues.


